
Wir empfehlen die Verwendung eines CPU- und Memory-optimierten Maschinentyps in einer europäischen Region. Für unsere Berechnungen haben wir im ersten Schritt den Typ c2-standard-60 mit 60 virtuellen CPUs (Intel Xeon bei 3.8 GHz) und 240 GB an Speicher verwendet. Dafür wurde die TensorFlow.js-Anwendung in 60 parallelen Prozessen gestartet und für jede Station ein eigenes Modell berechnet.

Die Verwendung von zugeschalteten GPUs wird nicht empfohlen, da die derzeitigen Modelle zu simpel sind um von der Auslagerung der Brechnung auf eine GPU profitieren zu können. Der hier auftretende Overhead beim Speichermanagement ist so hoch, dass die CPU-basierten Trainings weitaus schneller waren. Für unseren Test haben wir insgesamt 4 virtuelle NVIDIA Tesla V100-GPUs auf die virtuellen Compute Engine Instanz aufgeschaltet.

Als Eingabe-Datasets werden die CSV-Dateien vom öffentlichen Dataset-Bucket von SharedMobility.ai genommen. Diese können unter der URL https://storage.googleapis.com/smai-public-datasets/ jederzeit heruntergeladen werden. Im Verzeichnis sharedmobility-ai/prediction/citybikewien-tfjs führt man anschließend eine Trainins-Session aus:
node src/index.js dataset https://storage.googleapis.com/smai-public-datasets/…url…to…csv /my/output/dir/
Das gesamte Beispiel-Script ist im Github-Repository unter /prediction/_scripts/train-with-datasets.sh veröffentlicht.
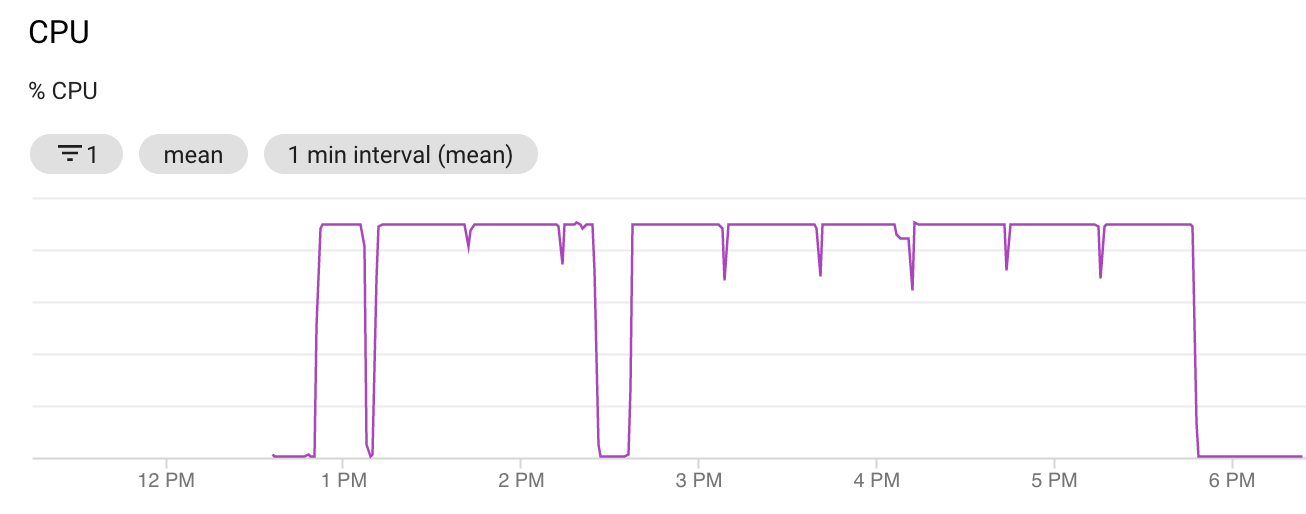
Auslastung während des Trainings
Um eine optimale Auslastung zu erreichen trainieren wir unsere Modelle parallel. Dafür starten wir den Prozess mit dem nohup POSIX-Befehl und stellen so eine relativ simple Batchverarbeitung her. Dadurch kann man sich während der relativ langen Trainings-Sessions, die über mehrer Stunden laufen können, jederzeit vom Terminal ausloggen bzw. die Verbindung zum Server verlieren. Startet man das Trainings-Skript ohne nohup, so wird das Training augenblicklich mit dem Ende der Terminal-Session beendet.
Das train-with-datasets.sh Skript wartet absichtlich alle 15 parallelen Ausführungen zusammen, um so eine Überlastung zu vermeiden und dem Host-Betriebssystem genügend Zeit einzuräumen um die Altlasten der vorherigen Ausführungen zu beseitigen. Dies zeigt sich auch im CPU-Graph durch kleinere Spikes nach unten in regelmäßigen Abständen.
Kosten und Kostenstruktur
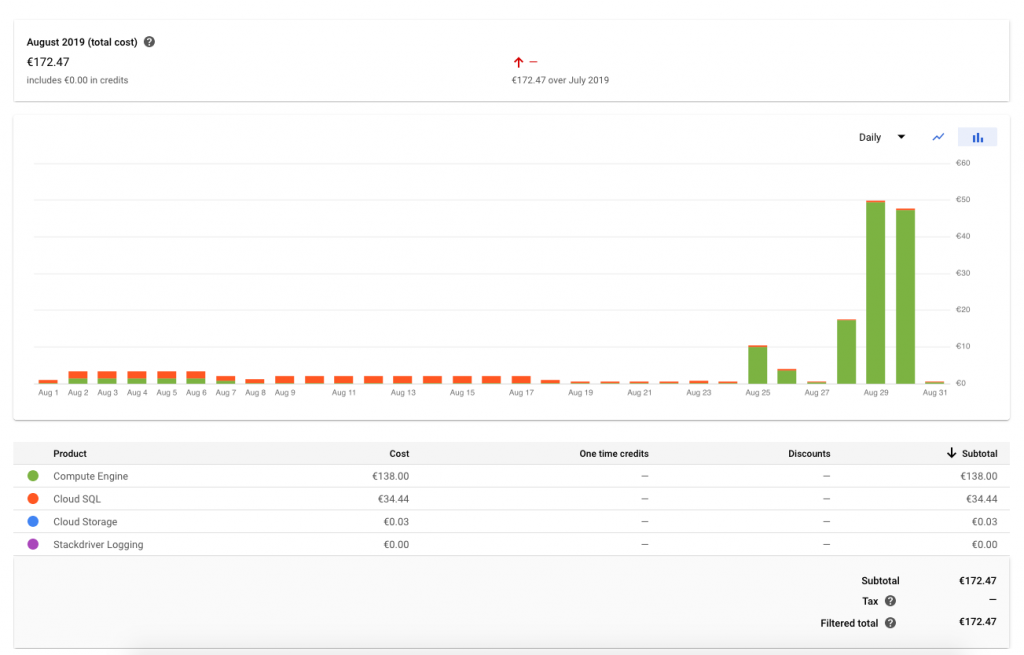
In der Spitze verwendet verwendete SharedMobility.ai zum Training eine Virtuelle Maschine vom c2-standard-60 Maschinentyp. Die reinen Maschinenkosten dafür liegen bei USD 3,13 pro Stunde, was gut USD 75 pro Tag bedeutet (Stand August 2019). Die CPU-Kosten und Memory-Kosten teilen sich dabei in etwa im Verhältnis 50 zu 50 auf. Hier die genaue Kostenaufstellung unserer Trainings:
Die oben angeführten Kosten können nicht nur nach Cloud-Produktgruppe, sondern auch in die einzelnen Kostenbestandteile aufgeteilt werden. Hier zeigt sich, dass CPU und Memory in etwa im selben Verhältnis anfallen.
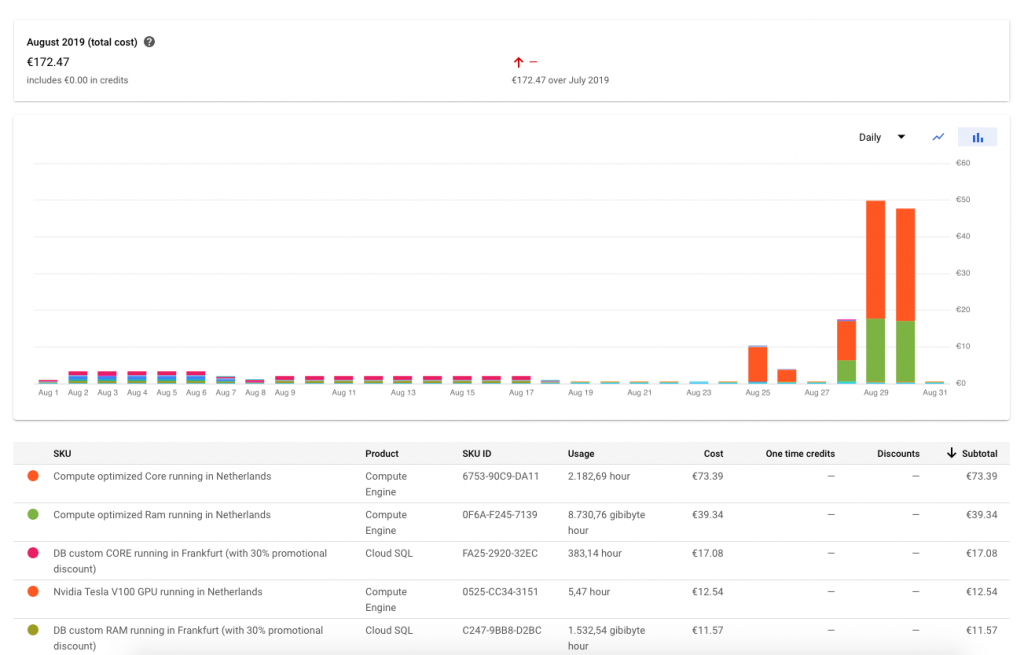
Die Nvidia Tesla V100 GPUs im europe-west4 Rechenzentrum sind trotz der geringen Einsatzzeit ein spürbarer Kostenfaktor. Eine V100 GPU kostet pro Stunde rund 2,30 Euro.